
In this blog post we are looking into schema evolution with Confluent Schema Registry. Kakfa doesn’t do any data verification it just accepts bytes as input without even loading into memory. The consumers might break if the producers send wrong data, for example by renaming a field. The Schema Registry takes the responsibility to validate the data. It is a separate component to which both the consumers and producers talk to. It supports Apache Avro as the data format.
Start Kafka
We are starting Kafka with docker-compose using the lensesio/fast-data-dev image. This will also startup other services like Confluent Schema Registry which we will need later on.
version: '3'
services:
kafka-cluster:
image: lensesio/fast-data-dev
container_name: fast-data-dev
environment:
ADV_HOST: 127.0.0.1 # Change to 192.168.99.100 if using Docker Toolbox
RUNTESTS: 0 # Disable Running tests so the cluster starts faster
FORWARDLOGS: 0 # Disable running 5 file source connectors that bring application logs into Kafka topics
SAMPLEDATA: 0 # Do not create sea_vessel_position_reports, nyc_yellow_taxi_trip_data, reddit_posts topics with sample Avro records.
ports:
- 2181:2181 # Zookeeper
- 3030:3030 # Lensesio UI
- 8081-8083:8081-8083 # REST Proxy, Schema Registry, Kafka Connect ports
- 9581-9585:9581-9585 # JMX Ports
- 9092:9092 # Kafka Broker
Before you start up the services make sure you increase the RAM for at least 4GB in your Docker for Mac/Windows settings.
To start up the services use this command:
$ docker-compose up -d
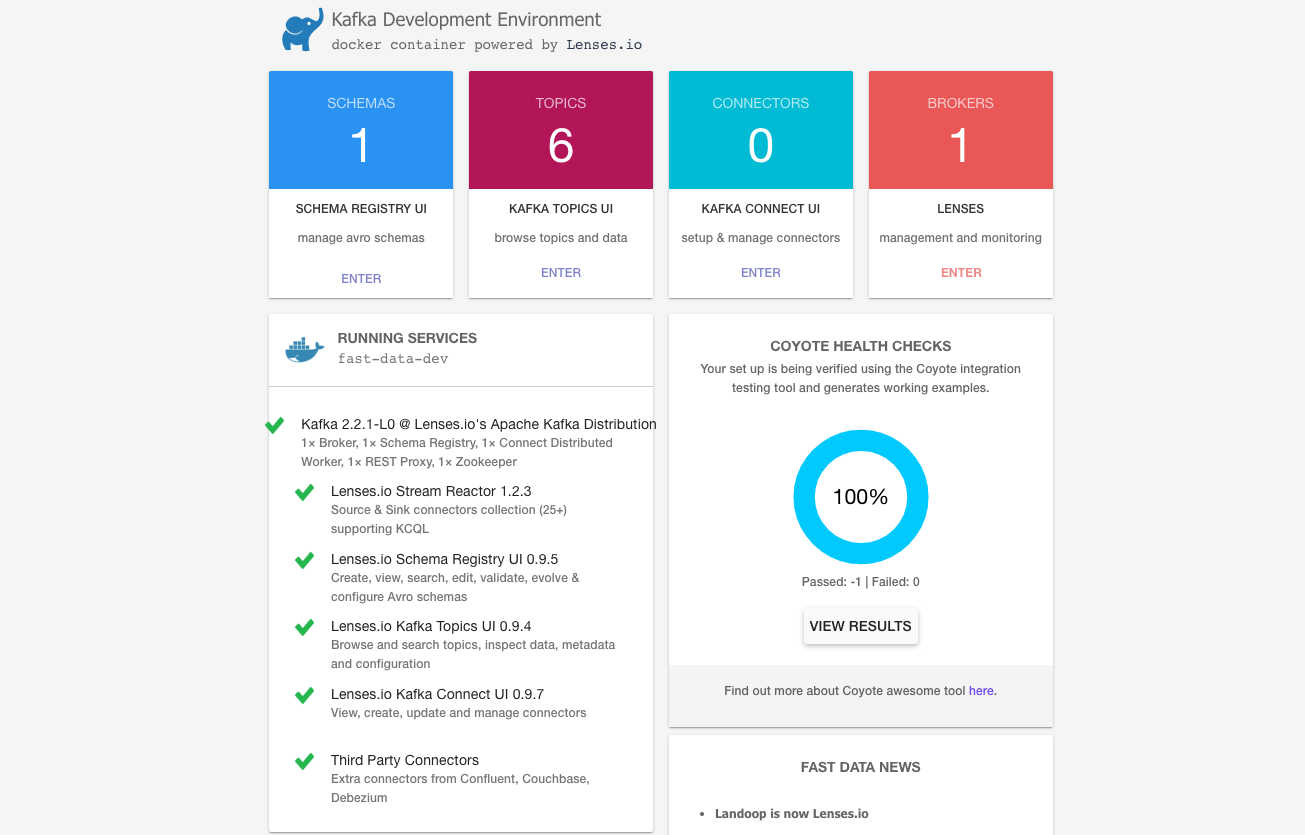
Open the Lensesio UI in a browser http://localhost:3030
Avro
Avro is a language independent, schema-based data serialization library. The schema is specified in a JSON format.
It has the following primitive data types:
null- No value.boolean- A binary value.int- A 32-bit signed integer.long- A 64-bit signed integer.float- A single precision (32 bit) IEEE 754 floating-point numberdouble- A double precision (64-bit) IEEE 754 floating-point number.byte- A sequence of 8-bit unsigned bytes.string- A Unicode character sequence.
Complex types:
record
{
"namespace": "com.github.altfatterz.avro",
"name": "Customer",
"type": "record",
"fields": [
{
"name": "first_name",
"type": "string",
"doc": "the first name of the customer"
},
{
"name": "last_name",
"type": "string",
"doc": "the last name of the customer"
}
]
}
enum
{
"type" : "enum",
"name" : "Colors",
"symbols" : ["WHITE", "BLUE", "GREEN", "RED", "BLACK"]
}
array
{"type" : "array", "items" : "string"}
map
{"type" : "map", "values" : "int"}
union- they are represented as JSON array, and indicate that a field may have more than one type
{
"name": "phone_number",
"type": ["null","string"],
"default": null,
"doc": "the phone number of the customer"
}
More information about Avro you can find here
Avro Tools
Avro Tools is a command line utility to work with avro data.
Install
$ brew install avro-tools
Convert from json to avro:
$ avro-tools fromjson --schema-file src/main/resources/avro/schema.avsc customer.json > customer.avro
A customer.avro should be created.
Get the schema from customer.avro file:
$ avro-tools getschema customer.avro
The schema will be printed to the standard output.
Convert from avro to json:
$ avro-tools tojson --pretty customer.avro
Confluent Schema Registry
Avro schemas are stored in the Confluent Schema Registry. A producer sends avro content to Kafka and the schema to Schema Registry, similarly a consumer will get the schema from Schema Registry and will read the avro content from Kafka.
Kafka Avro Console Producer and Consumer
These tools come with the Confluent Schema Registry and allow to send avro data to Kafka. The fastest way to get the binaries is using docker run
$ docker run --net=host -it confluentinc/cp-schema-registry:5.3.2 /bin/bash
Let’s start first the kafka-avro-console-consumer with the following command:
$ kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic mytopic \
--from-beginning \
--property schema.registry.url=http://localhost:8081
Then in another terminal start the kafka-avro-console-producer with the following command:
$ kafka-avro-console-producer --broker-list localhost:9092 --topic mytopic \
--property schema.registry.url=http://localhost:8081 \
--property value.schema='{"type":"record", "name":"Customer", "fields":[{"name":"first_name", "type":"string"}] }'
And now we can send data:
{"first_name":"Zoltan"}
{"first_name":"Kasia"}
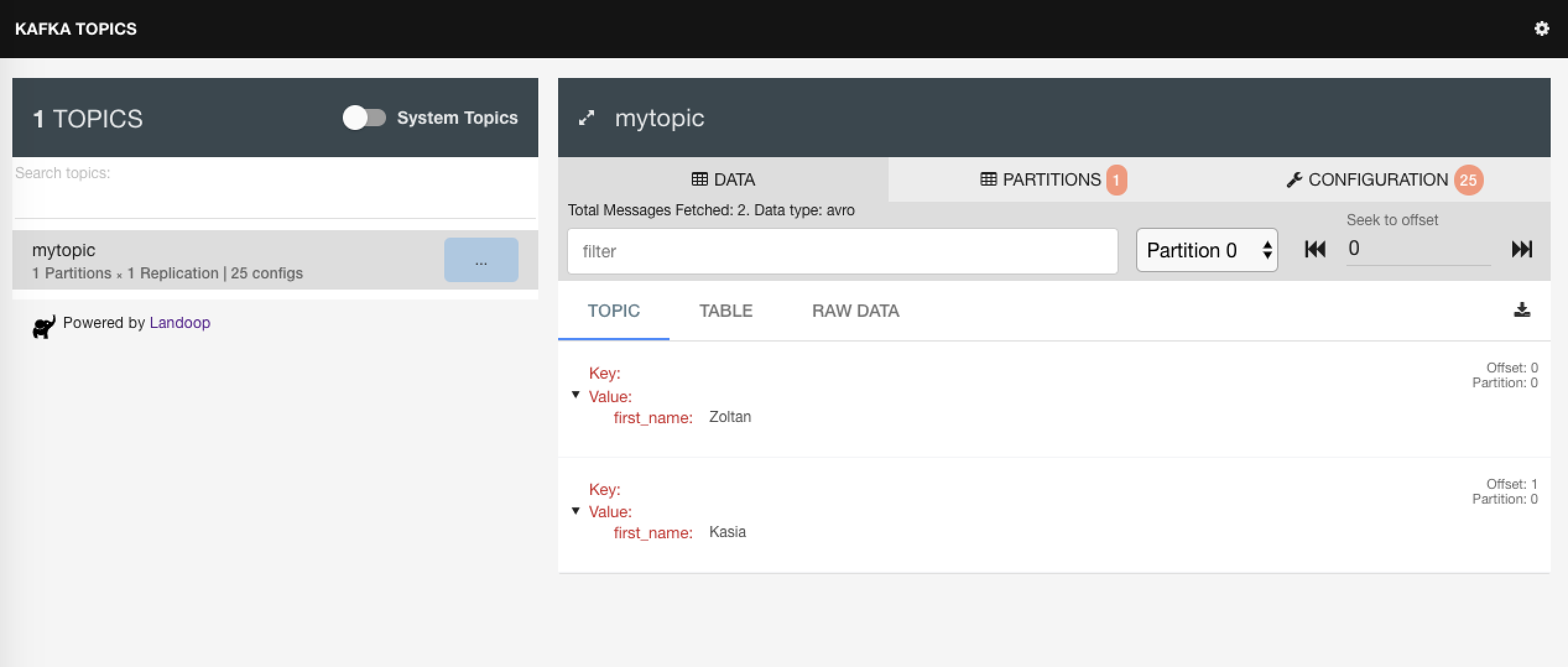
Now if we check the kafka-avro-console-consumer it should have received the data. In the kafka-topics-ui we can see that the mytopic topic was created and the data inside the topic has avro data type.
If we send the wrong field name or wrong data type as the field value we get an error:
{"name":"Zoltan"}
org.apache.kafka.common.errors.SerializationException: Error deserializing json {"name":"Zoltan"} to Avro of schema {"type":"record","name":"Customer","fields":[{"name":"first_name","type":"string"}]}
Caused by: org.apache.avro.AvroTypeException: Expected field name not found: first_name
Kafka Avro Producer and Consumer with Java
Compared to the simple KafkaProducer and KafkaConsumer discussed in a previous blog post https://zoltanaltfatter.com/2019/11/23/kafka-basics/ we need to configure a few things:
KafkaConsumer
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class.getName());
properties.setProperty("specific.avro.reader", "true");
properties.setProperty("schema.registry.url", "http://localhost:8081");
KafkaProducer
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
properties.setProperty("schema.registry.url", "http://localhost:8081");
The complete source code can be found here.
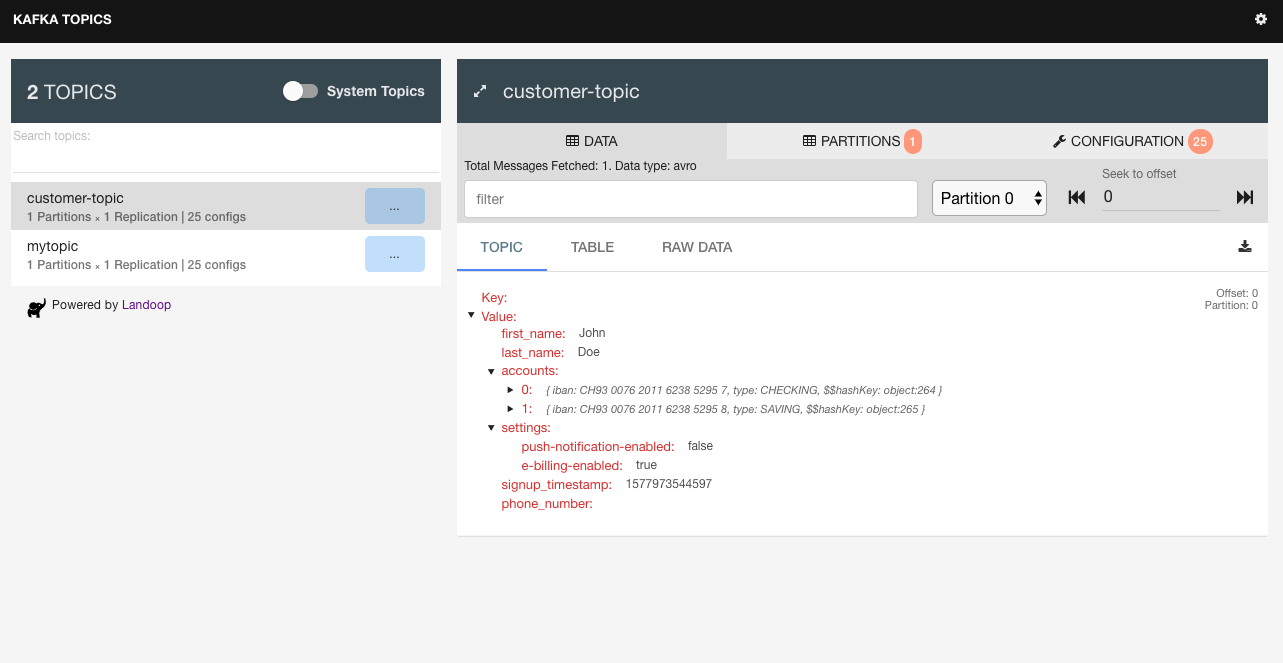
With the Kafka Topics UI we can inspect the produced message:
Schema evolution
We get errors if we try to evolve a schema in a non-compatible way. For example let’s try to register another schema to the previous mytopic
$ kafka-avro-console-producer --broker-list localhost:9092 --topic mytopic \
--property schema.registry.url=http://localhost:8081 \
--property value.schema='{"type":"string"}'
As soon as we type a string value we will get the following error:
org.apache.kafka.common.errors.SerializationException: Error registering Avro schema: "string"
Caused by: io.confluent.kafka.schemaregistry.client.rest.exceptions.RestClientException: Schema being registered is incompatible with an earlier schema; error code: 409
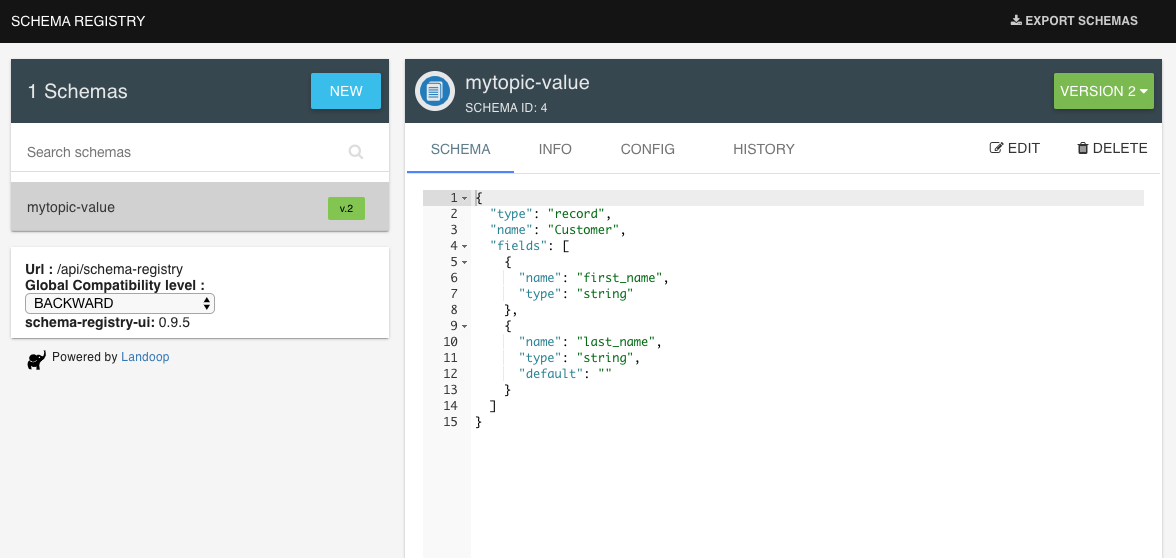
Let’s evolve the schema by adding another field which has a default value.
$ kafka-avro-console-producer --broker-list localhost:9092 --topic mytopic \
--property schema.registry.url=http://localhost:8081 \
--property value.schema='{"type":"record", "name":"Customer", "fields":[{"name":"first_name", "type":"string"}, {"name":"last_name", "type":"string", "default":"" }] }'
{"first_name":"John", "last_name":"Doe"}
We should not get error this time and we should see another version of the schema registered:
Conclusion
In this blog post we looked into
- Apache Avro
- Confluent Container Registry
- Kafka Avro Console Producer and Consumer
- Kafka Avro Producer and Consumer with Java
- Schema Evolution
The source code of the examples can be found here: https://github.com/altfatterz/learning-kafka/tree/master/schema-registry/avro-examples